
концепция проекта
Центральная идея проекта — создание образов с эффектом размытия. Мне хотелось, чтобы получившиеся изображения передавали ощущение воспоминаний: они так же размыты и эфемерны, в них так же утрачены детали, а оставшийся силуэт, словно врезавшийся в память образ, вызывает чувство ностальгии и пробуждает ассоциации.
исходные изображения


В качестве изображений для обучения модели я собрала датасет из 143 файлов с фотостока Unsplash с открытой лицензией «Unsplash License», которая разрешает свободное использование изображений в любых целях.


С визуальной точки зрения были отобраны изображения, демонстрирующие различные степени и характер размытия: от едва уловимой мягкости фона до размытия, возникающего в движении, где очертания предметов почти растворяются и становятся лишь намёком на исходную форму.
процесс обучения модели
Сначала я установила все необходимые библиотеки, а также загрузила датасет и сохранила его в нужную директорию.
Следующий шаг — описание каждого изображения из моего датасета с помощью нейросети BLIP. Эти текстовые описания затем использовались как подписи к изображениям, чтобы обучаемая модель могла лучше понять содержание кадров и связать визуальный стиль размытия с конкретными сценами и объектами.
Самая главная часть — само обучение модели на основе Stable Diffusion с помощью метода DreamBooth LoRA, чтобы она переняла характерный эффект размытия и начала воспроизводить его в новых генерациях.
На этом этапе я выгрузила модель на Hugging Face, после чего загрузила базовую модель Stable Diffusion XL и специальный VAE, а затем подключила обученные LoRA-веса, в которых уже содержался выученный стиль размытия. После этого модель переносилась на GPU, чтобы можно было генерировать новые изображения, уже применяя к ним мой обученный эффект BLURRED.
результаты генераций


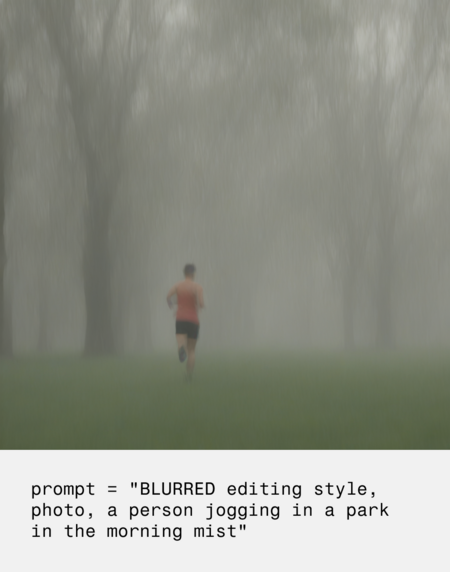


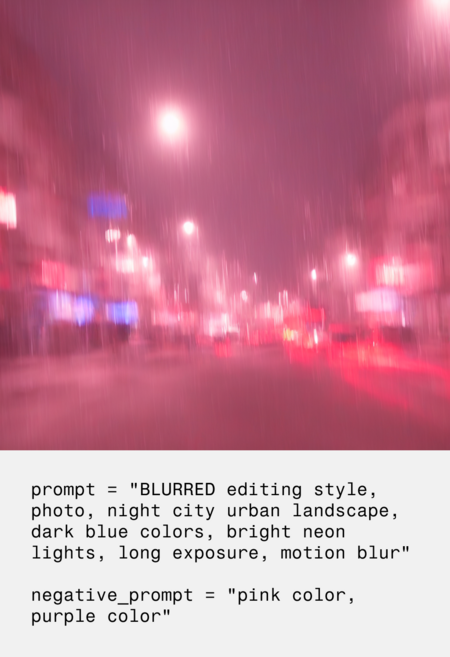














комментарий результатов
Итогом работы стала серия из 18 сгенерированных изображений, объединённых единой визуальностью.
Фотографии природных пейзажей, листьев и цветов в основном генерировались с моушн-блюром, так как в исходном датасете именно такой эффект чаще всего применяется к органическим объектам на фото. А вот изображения людей и животных чаще получались с мягким расфокусом или эффектом длинной выдержки, что также отражает визуальные особенности исходных фотографий, на которых строилось обучение.
Интересно, что обученная модель в большинстве случаев генерирует изображения в розоватых или зеленоватых оттенках. С одной стороны, это создаёт ощущение цельной визуальной стилистики и делает изображения узнаваемыми, но с другой — иногда цвет начинает доминировать там, где он не нужен, и в ряде случаев от навязчивого розового оттенка не удавалось полностью избавиться даже с помощью negative prompt.
Мне было очень интересно, получится ли у нейросети уловить и корректно воспроизвести длинную выдержку, размытие в движении или размытие случайных частей изображения. На мой взгляд, получилось успешно, и результат полностью оправдал ожидания.
описание применения генеративной модели
Stable Diffusion XL 1.0 Использовалась как основная генеративная модель, на базе которой создавались новые изображения.
BLIP (Bootstrapping Language-Image Pre-training) Применялась для автоматического создания текстовых описаний к изображениям обучающего датасета, чтобы связать визуальное содержание изображений с текстом и использовать эти данные при обучении.
Dreambooth + LoRA Использовались для дообучения базовой модели под конкретный визуальный стиль. DreamBooth позволил привязать стиль к модели, а LoRA — сделать это быстрее и с меньшими вычислительными затратами, обучая только небольшое количество параметров, а не всю модель целиком.
AutoencoderKL (VAE) Эта модель используется внутри Stable Diffusion и отвечает за преобразование изображения в латентное пространство и обратно.



