
Идея проекта
Проект посвящён исследованию авторского визуального стиля через инструменты генеративного искусственного интеллекта

В основе проекта лежит авторский стиль иллюстрации, разработанный ранее в рамках проекта MISS, посвящённого певице Доре и её музыкальному альбому.
Ключевой задачей проекта было не просто создание серии изображений, а интерпретация смыслов и эмоциональных состояний, заложенных в песнях, через визуальный образ. Каждая работа представляла собой попытку перевести музыкальное содержание в язык цвета, формы и фактуры, создавая визуальные метафоры к отдельным трекам.
В рамках проекта была создана серия из 13 живописных работ на холстах. Важную роль в формировании образа играла не только живопись, но и материальность поверхности: в работы добавлялись текстурные элементы, в частности кристаллы, которые усиливали ощущение физического присутствия и эмоциональной насыщенности.
В рамках проекта хотелось перенести разработанный визуальный стиль в генеративную среду. Основной задачей стало исследование того, способна ли генеративная модель не только воспроизводить общий визуальный язык, но и передавать более сложные характеристики стиля — такие как цветовая гамма, пластика формы и ощущение материальности.
Особый интерес представлял вопрос, может ли модель интерпретировать текстурность работ, включая эффекты, связанные с физическими материалами и поверхностью.
В этом контексте генеративная модель рассматривалась не как инструмент точного копирования или замены ручной работы, а как экспериментальная среда. Она использовалась для поиска новых визуальных решений, вариаций и неожиданных сочетаний цвета и формы, которые сложно получить в рамках традиционного процесса.
Для обучения модели был использован ограниченный датасет, сформированный на основе собственных живописных работ. В него вошли 13 изображений, созданных ранее в рамках проекта MISS.
Все работы изначально существовали как физические холсты, поэтому перед использованием были адаптированы: изображения были обрезаны и приведены к единому формату 512×512 для корректного обучения модели.




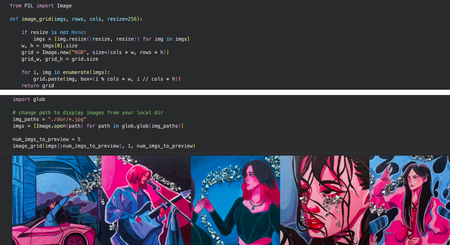
Первым этапом была настроена среда обучения в Google Colab: подключён GPU, установлены необходимые библиотеки (diffusers, transformers, accelerate, peft, bitsandbytes), а также загружен скрипт для дообучения модели Stable Diffusion XL с использованием метода DreamBooth и LoRA.
Далее был подготовлен обучающий датасет. Изображения, созданные ранее в рамках проекта MISS, были собраны в единую директорию и приведены к формату 512×512. Перед началом обучения структура датасета была проверена, включая корректность изображений и наличие файла metadata.jsonl с подписями.
Подписи к изображениям были сгенерированы автоматически с помощью модели BLIP и затем адаптированы под задачу обучения: к ним был добавлен кастомный префикс, отражающий авторский стиль (drawing in DORIK style). Все данные были сохранены в формате metadata.jsonl, который используется моделью в процессе обучения.
После подготовки данных была настроена среда обучения с использованием библиотеки accelerate, а также выполнена авторизация в Hugging Face для последующего сохранения модели.
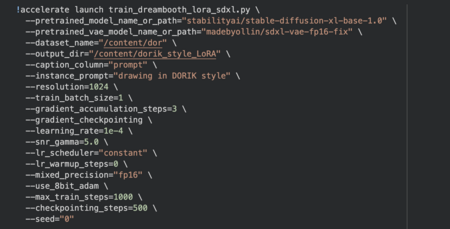
Обучение проводилось на базе модели Stable Diffusion XL с использованием метода DreamBooth + LoRA. Такой подход позволил адаптировать модель под авторский стиль без полного переобучения, сохраняя при этом возможности базовой модели.
Ключевые параметры обучения • Базовая модель: Stable Diffusion XL • Instance prompt: drawing in DORIK style • Размер изображений: 1024×1024 • Batch size: 1 • Gradient accumulation: 3 • Learning rate: 1e-4 • Шаги обучения: 1000 • Precision: fp16
После завершения обучения полученная LoRA-модель была сохранена и опубликована на платформе Hugging Face, что позволило обеспечить доступ к результатам и использовать модель в различных средах.
На финальном этапе обученная LoRA была подключена к базовой модели Stable Diffusion XL и использована для генерации изображений по текстовым запросам.
Особое внимание уделялось работе с промптами: формулировка запросов напрямую влияла на сохранение стиля, цветовой палитры и выразительности изображения.
Полученные генерации были сохранены и использованы для формирования итоговой визуальной серии проекта.
Генерация изображений

Все промпты для генерации выстраивались по единому принципу, позволяющему сохранять стиль и при этом варьировать образы:
— указание ключевого стиля (drawing in DORIK style) — описание персонажа или типа портрета — добавление характеристик, связанных с эмоцией, светом и деталями изображения
Такой подход позволял контролировать результат генерации и обеспечивал сохранение визуальной целостности серии.
При первой генерации был использован базовый промпт: «drawing in DORIK style, expressive face, stylized colors, detailed brush texture»
Уже на этом этапе модель выдала изображение, соответствующее общей стилистике проекта: были сохранены характерная цветовая гамма, живописность и эмоциональная выразительность образа.


Сгенерированные изображения
Сгенерированное изображение
Полученные изображения в целом соответствуют исходному авторскому стилю, что проявляется в ряде ключевых визуальных характеристик.
В первую очередь сохраняется общая структура: композиция выстраивается вокруг лица, которое остаётся центральным и наиболее проработанным элементом изображения. Это позволяет удерживать фокус на эмоциональном состоянии персонажа и делает образы цельными.
Одним из наиболее значимых результатов стало воспроизведение текстурности работ. Несмотря на то, что исходные изображения создавались в физической среде, модель в ряде случаев успешно передаёт ощущение поверхности холста и материальности изображения, включая живописную фактуру и мягкие переходы цвета.


Сгенерированное изображение / Оригинальное изображение
Также сохраняется характерная цветовая гамма проекта. Модель корректно воспроизводит основные цветовые сочетания и распределение цветовых пятен, что поддерживает визуальную целостность серии и делает изображения стилистически связанными между собой.
Отдельного внимания заслуживает передача дополнительных текстурных элементов. В частности, в генерациях прослеживается интерпретация кристаллов, которые использовались в оригинальных работах. Несмотря на их физическую природу, модель адаптирует этот элемент в цифровую форму, сохраняя его как визуальный акцент и часть стилистического языка.


Сгенерированное изображение / Оригинальное изображение
Усложнение промпта

Для разнообразия генераций промпты были усложнены за счёт добавления сюжетных элементов и окружения.
Помимо базовых портретов были протестированы: — сцены с простым окружением — изображения в полный рост — различные варианты освещения
Пример усложнённого промпта: «drawing in DORIK style, portrait of a girl sitting by the window, soft evening light, emotional атмосhere, detailed background»


Сгенерированные изображения
Сгенерированное изображение
Таким образом удалось получить более разнообразные визуальные решения, расширить диапазон сюжетов и протестировать новые сочетания формы, света и композиции внутри заданного стиля.


Сгенерированные изображения
Проблемные генерации
При генерации изображений возникали сложности даже при использовании относительно простых промптов. В ряде случаев из-за высокой степени абстракции портрет начинал искажаться: черты лица терялись, образ становился менее читаемым или вовсе отходил от человеческой формы.
Также наблюдались отклонения от заданного стиля, когда модель не полностью сохраняла характерные визуальные особенности.


Плохо сгенерированные изображения
Плохо сгенерированные изображения
Расширение границ стиля

В процессе генерации возникали изображения, которые не полностью соответствовали исходному стилю, однако представляли интерес с точки зрения визуального решения.
Отдельно можно отметить, что подобные изображения отличались более тёмной цветовой гаммой и мрачным настроением, что усиливало эмоциональную напряжённость и создавало иное восприятие образа.


Сгенерированные изображения
Такие результаты можно рассматривать как расширение границ стиля: модель не просто воспроизводит заданный язык, но и предлагает новые интерпретации, выходящие за его рамки.
Эти «отклонения» позволяют увидеть потенциал дальнейшего развития визуального подхода и могут служить источником новых художественных идей.


Сгенерированные изображения
Заключение
В рамках проекта была обучена генеративная модель, способная воспроизводить авторский стиль иллюстрации, основанный на живописных работах и интерпретации музыкальных образов.
Полученные результаты показывают, что даже при ограниченном датасете нейросеть способна уловить ключевые характеристики визуального языка — цветовую гамму, композицию, эмоциональное состояние и в ряде случаев передавать ощущение текстуры и материальности.
Лучшие сгенерированные изображения
Особый интерес представляет способность модели интерпретировать элементы, связанные с физическими материалами, такие как фактура холста и кристаллы, переводя их в цифровую форму и сохраняя их как часть стилистического кода.
Также проект показал, что генеративная модель может выступать не только как инструмент ускорения процесса, но и как экспериментальная среда для поиска новых визуальных решений, сочетаний цвета и формы, а также расширения границ исходного стиля.
Использованные инструменты
Kaggle — подготовка данных и первоначальная работа с датасетом https://www.kaggle.com
Google Colab — основная среда для обучения модели и генерации изображений с использованием GPU https://colab.research.google.com
Hugging Face — хранение и публикация обученной LoRA-модели, а также её последующее использование https://huggingface.co
ChatGPT — использовался для помощи в отладке кода, настройке среды и оптимизации процесса обучения модели https://chat.openai.com



