
Анализ и визуализация данных для задачи скоринговой модели
Обложка: генерация при помощи Leonardo.ai
Рубрикатор
1. Цель проекта 2. Введение 3. Библиотеки и загрузка данных 4. Проверка на пустые значения и типы данных 5. Обработка данных 6. Гипотезы 7. Изучение данных 7.1. Целевая переменная 7.1. Возраст 7.1. Образование 7.1. Corr 7.1. Доход 8. Анализ важных атрибутов 9. Заключение 10. Блокнот с кодом 11. Источники
Цель проекта:
Цель проекта — создать эффективную скоринговую модель для прогнозирования дефолтов среди вторичных клиентов банка. Для этого мы проанализируем множество переменных, характеризующих профиль заемщиков, используя данные из набора «[SF-DST] Credit Scoring» с платформы Kaggle.
Набор данных включает атрибуты, такие как уровень образования, пол, возраст, наличие автомобиля, количество отказов по прошлым заявкам и многие другие. Эти признаки помогут построить точную модель, предсказывающую вероятность дефолта.
Введение:
Были выбраны данные из набора «[SF-DST] Credit Scoring» на платформе Kaggle. Этот набор содержит разнообразные атрибуты заемщиков, такие как уровень образования, пол, возраст, наличие автомобиля, количество отказов по прошлым заявкам, доход, количество запросов в БКИ, и другие важные показатели.
Анализ этих данных представляет особую ценность, поскольку позволяет построить скоринговую модель, способную предсказать вероятность дефолта заемщиков. Это важно для банков, так как помогает им минимизировать риски, связанные с выдачей кредитов. Понимание факторов, влияющих на дефолт, может значительно улучшить процессы принятия решений и повысить финансовую стабильность банка.
В анализе данных использовались различные виды графиков: линейные графики, гистограммы, столбчатые диаграммы, сложенные графики, тепловая карта, boxplot
Описание полей:
client_id — идентификатор клиента education — уровень образования sex — пол заемщика age — возраст заемщика car — наличие автомобиля car_type — флаг иностранного автомобиля decline_app_cnt — количество отклоненных заявок в прошлом good_work — флаг наличия «хорошей» работы bki_request_cnt — количество запросов в БКИ home_address — категория домашнего адреса work_address — категория рабочего адреса income — доход заемщика foreign_passport — наличие заграничного паспорта sna — связь заемщика с клиентами банка first_time — возраст наличия информации о заемщике score_bki — скоринговый балл по данным БКИ region_rating — рейтинг региона app_date — дата подачи заявки default — флаг дефолта по кредиту
Библиотеки и загрузка данных
Проверка на пустые значения и типы данных
Проверка на пустые значения необходима, в данном случае в колонке education отсутствует ряд данных.
При этом можно заметить, что большинство колонок содержат типы данных int64.
Обработка данных
Рассчитаем в процентном соотношении количество пропусков: data['education'].isnull ().sum () / data.shape[0]100
Разрыв в графе «Образование» составляет около 41,599%
Заменим их на самые часто встречаемые результаты в выборке: ed_mode = data['education'].mode ()[0] data['education'] = data['education'].fillna (ed_mode)
Гипотезы
1. Возраст Быстрый ответ «хороших» заемщиков больше по сравнению с «плохими» заемщиками (распределение возраста в зависимости от флага дефолта смещено вверх при default=0).
2. Уровень образования зависит от возраста, что также влияет на погашение кредита. Люди с более высоким образованием чаще являются «хорошими» заемщиками.
3. При good_work = 0 риск дефолта по кредиту увеличивается (флаг дефолта).
4. Доход «хороших» заемщиков выше по сравнению с «плохими» заемщиками (распределение доходов в зависимости от флага дефолта смещено вверх при default=0).
5. score_bki напрямую коррелирует с default: чем ниже score_bki, тем выше вероятность того, что клиент погасит кредит банку.
Изучение данных: целевая переменная
Превалирование платежеспособных клиентов: Большинство клиентов, 87,3%, не допускают дефолта. Это указывает на то, что большая часть заемщиков успешно обслуживает свои кредиты.
Риск дефолта: Около 12,7% клиентов допустили дефолт, что является значительным показателем, требующим внимания.
Изучение данных: возраст
Кривые показывают, что заемщики без дефолта (default 0) имеют слегка смещенное распределение возраста в сторону более старших возрастов по сравнению с заемщиками с дефолтом (default 1). Это подтверждает гипотезу, что «хорошие» заемщики в среднем старше «плохих» заемщиков.
На графике плотности видно, что кривая для заемщиков без дефолта (default 0) имеет пик немного правее и выше по сравнению с кривой для заемщиков с дефолтом (default 1). Это также указывает на то, что возраст заемщиков без дефолта в среднем выше.
1. Модальный возраст (наиболее часто встречающийся возраст):
Модальный возраст заемщиков без дефолта (default 0) составляет 31 год. Модальный возраст заемщиков с дефолтом (default 1) составляет 26 лет.
Это подтверждает, что среди заемщиков без дефолта чаще встречаются люди старше, чем среди заемщиков с дефолтом.
2. Средний возраст:
Средний возраст заемщиков без дефолта (default 0) составляет 39.39 лет. Средний возраст заемщиков с дефолтом (default 1) составляет 38.53 года.
Эти данные показывают, что средний возраст заемщиков без дефолта немного выше среднего возраста заемщиков с дефолтом. В разделе «default» наблюдаются небольшие различия по возрасту, гипотеза подтверждается
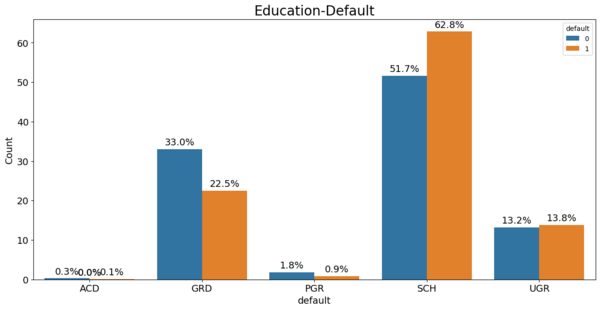
Изучение данных: образование
Если взять образование SCH, то возраст смещен в большую сторону, по сравнению с тем же UGR. Для ACD характерно смещение возрастного распределения влево, если сравнивать с PGR, что в принципе понятно.
Самые молодые — это UGR, и предполагается, что в значительной степени они будут «плохими» заемщиками.
Из графика можно сделать вывод, что с ростом уровня образования медиана возраста заемщиков уменьшается. Наибольший разброс возраста наблюдается у заемщиков с начальным и академическим образованием.
Видно, что если взять уровень образования PGR и ACD, то средний возраст «плохих» заемщиков выше, чем у «хороших», но разброс значений обоих показателей также велик. Возможно, если взять некий возрастной предел, например, от 30 до 50 лет, то в рамках этой группы данный показатель не будет сильно влиять на полноту погашения кредита.
Аналогично, мы видим, что процент недобросовестных заёмщиков выше с уровнем образования SCH', для UGR' разница не существенна.
Скорее, в данном случае влияет не сам возраст, а уровень образования. Также можно отменить, что в некоторой степени УГР более стабильны в плане выплат.
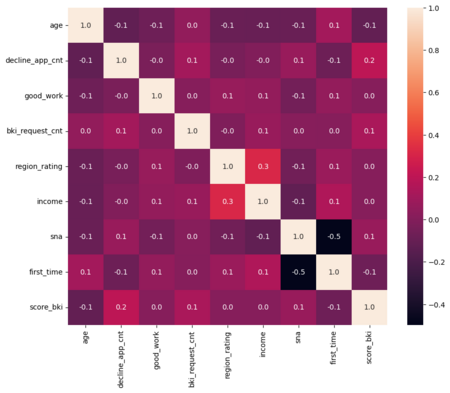
Изучение данных: Corr
По данной тепловой карте можно сделать выводы:
1. Высоких корреляций (положительных или отрицательных) нет, что указывает на слабые связи между переменными.
2. Наиболее заметная отрицательная корреляция между sna и first_time (-0.5), что предполагает, что чем больше время с момента первой регистрации, тем меньше количество социальных связей.
3. Положительная корреляция между region_rating и income (0.3), что логично, так как в регионах с более высоким рейтингом доходы могут быть выше.
Изучение данных: доход
Распределение доходов не равномерно, и для этого анализа достаточно длинных хвостов.
Распределение доходов: Обе группы демонстрируют широкий диапазон доходов с множеством выбросов. Это указывает на то, что, хотя большинство лиц имеют доходы, сосредоточенные вокруг медианы, есть несколько лиц с исключительными высокими доходами.
Центральная тенденция: Лица, не допустившие дефолт, имеют тенденцию к более высокому среднему и медианному доходу по сравнению с дефолтерами. Это может указывать на корреляцию между высоким доходом и способностью избежать дефолта по кредитам.
Разброс: Схожий разброс доходов между двумя группами свидетельствует о том, что изменчивость доходов сопоставима независимо от статуса дефолта.
Средний доход: 1. Лица, не допустившие дефолт (default = 0): Средний доход примерно 41,800 долларов. 2. Лица, допустившие дефолт (default = 1): Средний доход примерно 36,300 долларов.
Наблюдение: В среднем, лица, не допустившие дефолт, имеют более высокий доход по сравнению с дефолтерами.
Медианный доход: 1. Лица, не допустившие дефолт (default = 0): 2. Медианный доход составляет 30,000 долларов. Лица, допустившие дефолт (default = 1): Медианный доход составляет 28,000 долларов.
Наблюдение: Медианный доход для лиц, не допустивших дефолт, немного выше, чем у дефолтеров.
Видно, что ACD и PGR смещены в правую сторону, что может означать, что они являются лучшими заемщиками по кредиту, чем SCH и UGR.
Мы исследуем распределения числовых данных. Возраст, количество приложений decline_app_cnt и bki_request_cnt, а также доход Income не являются нормально распределенными.
Некоторые признаки, такие как age и income, имеют распределение, близкое к нормальному.
Признаки decline_app_cnt и bki_request_cnt имеют асимметричное распределение с большой концентрацией значений около нуля, что указывает на то, что у большинства наблюдений небольшое количество отклоненных заявок и запросов в бюро кредитных историй.
Признак score_bki также распределен по нормальному закону, что свидетельствует о вариациях кредитного балла вокруг среднего значения.
Анализ важных атрибутов
Признаки расположены по степени их важности вдоль оси OY, ось OX представляет значение Шепли. Каждая точка является отдельным наблюдением.
Цвет указывает значения соответствующего атрибута: синий — высокие, салатовый — низкие.
Рассмотрим пример: чем больше значение score_bki, тем выше вероятность дефолта; чем больше значение атрибута age, тем ниже вероятность дефолта.
Сравним с весами из логистической регрессии и проверим на нескольких признаках.
Заключение
Проект направлен на разработку эффективной скоринговой модели для вторичных клиентов банка, чтобы предсказать вероятность дефолта. В ходе работы был проведен тщательный анализ множества переменных, характеризующих профиль заемщиков, что позволило выявить значимые факторы, влияющие на вероятность дефолта.
Цветовое решение
Изначально графики не имели единой палитры и содержали разнообразные цвета, поскольку мне хотелось создать нечто яркое.
Однако, в последний момент я решила придерживаться одной темы и выбрала зеленый цвет и монохром. На некоторых графиках подобное цветовое решение мешало считыванию информации и пришлось использовать исходные варианты. Я решила применить умения с прошлого курса и моего основного направления и воспользовалась нейросетями и фотошопом, чтобы изменить гамму.
Источники
1. Google Colab 2. Pandas 3. Kaggle 4. iFoto 5. Leonardo.ai 6. Photoshop
")
")

")